VERÖFFENTLICHUNGEN

Anpassung der automatisierten Übersetzung bei Janus
Bei Janus kommen verschiedene Technologien der automatisierten Übersetzung zum Einsatz – die maschinelle Übersetzung (MT) und die KI-gestützte Übersetzung. Beide Technologien haben eine Reihe von Vor- und Nachteilen, die durch bestimmte Anpassungsmethoden ausgeglichen werden, sodass jede dieser Technologien für bestimmte Übersetzungsaufgaben geeignet ist.
Bei der Anpassung oder Feinabstimmung (Fine-Tuning) werden breit angelegte Basismodelle (Stock-Modelle) anhand fachspezifischer linguistischer Daten (Übersetzungen aus einem bestimmten Fachgebiet und/oder einer Sprachkombination) trainiert. Das Ergebnis sind spezialisierte maßgeschneiderte Modelle, die Texte derselben Thematik, Sprachkombination usw. besser übersetzen als die Materialien, die zum Training verwendet wurden. Die Anpassung maschineller Übersetzungssysteme erfolgt durch das Training der Stockmodelle ModernMT und Opus, während die Anpassung der KI-Systeme (bei Janus werden hauptsächlich Modelle der GPT-Reihe verwendet) entweder direkt auf der Website von OpenAI oder durch Hinzufügen der erforderlichen Sprachinformationen über eine Text-Eingabeaufforderung (Prompt), die an das KI-Modell gesendet wird, erfolgt. Für das Training des MT-Systems Opus und entsprechende Ergebnisse nach dem Training der ModernMT-Modelle werden mindestens 5000 Übersetzungssegmente benötigt.
Seltene Sprachkombinationen. In einigen Fällen, zum Beispiel bei seltenen Sprachkombinationen können MT-Systeme nicht angepasst werden, weil keine Standardmodelle für diese Sprachkombinationen vorhanden sind. In solchen Fällen kommen KI-Systeme zum Einsatz, die zuvor anhand großer Datenmengen trainiert wurden. Ein anschauliches Beispiel sind Übersetzungen aus dem Russischen ins Usbekische (lateinisch). Für diese Sprachkombination fehlten nicht nur grundlegende MT-Modelle, sie wurde auch von den Standard-Engines Google, DeepL und ModernMT nicht unterstützt. Das KI-System gpt-4o konnte die Übersetzung jedoch mit einer recht akzeptablen Qualität bewältigen (alle Bewertungen liegen über 50 von 100 Punkten). Nachfolgend sind die Ergebnisse der automatischen Bewertung der Übersetzungsqualität für die Sprachkombination ru-RU – uz-Latn-UZ aufgeführt.
| KI | KI mit Glossar | KI mit Glossar und Übersetzungsspeicher (TM) | |
| Bewertung von HLEPOR | 62,7 | 66,43 | 74,93 |
Bei der Anpassung von MT-Systemen und KI-Systemen sind nicht nur die vorhandenen Sprachdaten zu berücksichtigen, sondern auch die Besonderheiten ihrer Darstellung.
Format. Es gibt Unterschiede im Format der Daten, mit denen die MT- und KI-Systeme trainiert werden können. MT-Systeme können derzeit anhand von Übersetzungsdateien im Format .tmx trainiert werden. Das Dateiformat für KI ist abhängig von der Art des Trainings. Zur Anpassung des Modells auf der Website wird das Format .tmx verwendet. Um zusätzliche Informationen einzufügen, wird eine Textdatei im Format „Segment: Übersetzung“ benötigt.
Umfang. Es gibt auch Einschränkungen hinsichtlich des Umfangs der für die Anpassung bereitgestellten Sprachmaterialien. Bei der Arbeit mit KI-Systemen gibt es Einschränkungen hinsichtlich des Ressourcenverbrauchs und der Kosten für die an ein KI-Modell gesendeten Anfragen. Die Kosten einer Anfrage werden anhand der Länge des Textprompts und der Anzahl der Tokens berechnet. Ein Token entspricht etwa 0,75 Wörtern. Häufig wird eine Eingabeaufforderung durch Hinzufügen eines Übersetzungsspeichers oder Glossars zu umfangreich. Das wirkt sich auf den Preis aus und macht die Verwendung ineffizient. Beim Training von MP-Systemen ist das Gegenteil der Fall: Je umfangreicher das Trainingsmaterial, desto höher ist die Übersetzungsqualität nach dem Training.
Glossar. Derzeit können die MT-Systeme Opus und ModernMT Glossare im Standardformat „Begriff – Übersetzung“ bei der Übersetzung von Texten nicht verarbeiten. Die Glossare müssen in Übersetzungsspeicher konvertiert werden, wobei der Prozentsatz der übereinstimmenden Begriffe in der Übersetzung und im Glossar relativ gering ist. Glossare können auf unterschiedliche Weise in KI-Systeme integriert werden. Eine Möglichkeit besteht darin, das Glossar im Textformat unmittelbar in der Eingabeaufforderung hinzuzufügen. Die zweite Möglich ist, das Glossar im Format RAG (Retrieval Augmented Generation) zu integrieren. Nachfolgend ist die Übereinstimmung der Begriffe im Glossar und Übersetzungstext in Prozent angegeben.
| Maschinelle Übersetzung | KI-Übersetzung | |
| Übereinstimmung (Term Match Rate, TMR) in Prozent | 54,43 % | 78,48 % |
| Genauigkeit | 62,02 % | 92,4 % |
| Vollständigkeit | 62,02 % | 92,4 % |
Wie in der Tabelle zu sehen ist, ist der Prozentanteil der Begriffsübereinstimmungen beim Training von MT-Systemen anhand von Glossarbegriffen als Übersetzungsspeicher viel niedriger als die Übereinstimmung bei der Integration des Glossars in das KI-Modell. Die Auswahl der Anpassung der automatisierten Übersetzung je nach Sprachmaterial, das für das Training verwendet wird, stellt sich wie folgt dar.
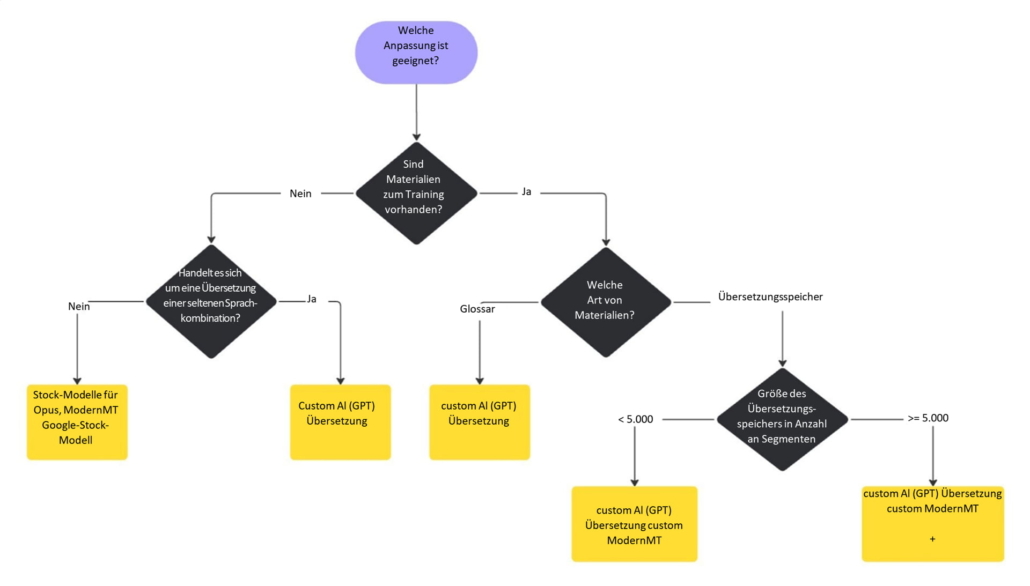
In der modernen Welt der automatisierten Übersetzung gibt es keine universellen Lösungen. Die Entscheidung zwischen maschineller Übersetzung und KI-Modellen ist häufig abhängig von den konkreten Aufgaben, der Sprachkombination und den für die Anpassung verfügbaren Sprachdaten. Janus kombiniert beide Ansätze erfolgreich und nutzt die Anpassung zur Entwicklung hochspezialisierter Modelle für die Übersetzung von Texten in bestimmten Themenbereichen und Sprachkombinationen.

Spezialistin für maschinelle Übersetzung
Ksenia Dmitrijewa
Ksenia ist seit 2024 als MT-Spezialistin in der Forschungs- und Entwicklungsabteilung von Janus tätig. Sie hat einen Bachelor in Übersetzungswissenschaft der Staatlichen Pädagogischen Herzen-Universität und absolviert derzeit ihren Masterstudiengang im Fachbereich „Digitale Linguistik“. Ksenia ist spezialisiert auf das Training von maschinellen Übersetzungssystemen (MT) und LLM (KI) zur Verbesserung der Übersetzungsqualität und Anpassung der Lösungen an die Anforderungen einer bestimmten Branche sowie auf die Bewertung der Übersetzungsqualität mithilfe automatischer Metriken (wie BLEU, TER, BERTScore).









