PUBLICATIONS

Customization of Automatic Translation at Janus
Janus successfully uses various automated translation technologies: machine translation (MT) and translation using artificial intelligence. As well as advantages, both technologies have their disadvantages, which are offset by certain customization methods, making each technology suitable for specific translation tasks.
Customization, or fine-tuning, refers to training general-purpose (stock) models on highly specialized language data (translations in a specific field and/or language pair). The result is a specialized custom model that will translate texts of the same subject matter, language pair, etc. more accurately as per the training materials. Machine Translation systems are customized by training ModernMT and Opus stock models, while AI systems (Janus mainly uses GPT models) are either customized directly on the OpenAI website, or by adding the necessary language information to the text prompt sent to the AI model. A translation memory of at least 5,000 segments is required to train Opus MT systems and obtain visible results after training ModernMT models.
Rare language pairs. In some cases, such as when working with rare language pairs, customization of machine translation systems may not be possible due to the lack of stock models for that pair. In these cases, AI systems come to the rescue, as they have been pre-trained with large datasets. An example of this is translation from Russian into Uzbek (Latin script). Not only were there no general-purpose MT models for this language pair, but it was also not supported by the stock Google, DeepL and ModernMT engines. However, the gpt-4o AI system managed to translate with relatively acceptable quality (all scores above 50 out of 100). Below are the results of automatic translation quality assessment for the ru-RU—uz-Latn-UZ language pair.
| AI | AI with glossary added | AI with glossary and TM added | |
| hLEPOR score | 62.7 | 66.43 | 74.93 |
When customizing both MT and AI systems, it is necessary to not only consider the availability of language data, but also how it is represented.
Format. There are differences in the data format that can be used to train MT and AI systems. Currently, MT systems can be trained on translation memory files in .tmx format. The file format for AI depends on the training method. To customize a model on the website, the .tmx format is required. To add additional information to the text prompt, you need a .txt text file in the format: “segment: translation”.
Volume. There are also restrictions on the volume of language materials to be provided for customization. When working with AI systems, the restrictions relate to resource consumption and the cost of each request sent to the AI model. The cost of a single request is calculated based on the volume of the text prompt and the number of tokens. One token is approximately 0.75 words. Often, when adding a translation memory or glossary, the prompt becomes extremely large, which affects the price, making its use inefficient. With regard to training MT systems, the opposite holds true: the larger the volume of training materials, the higher the quality of the translation after training.
Glossary. Currently, the Opus and ModernMT MT systems cannot use glossaries in the conventional “term–translation” format when translating texts. They need to be converted into translation memory. However, the percentage of term matches in the translation and glossary will be relatively small. Glossaries can be connected to AI systems in several ways. The first is to add a glossary in text format directly to the prompt. The second is to connect the glossary in RAG (Retrieval Augmented Generation) format. Below is the percentage of term matches in a glossary and in the translation text.
| Machine Translation | AI Translation | |
| Term Match Rate (TMR) | 54.43% | 78.48% |
| Accuracy | 62.02% | 92.4% |
| Completeness | 62.02% | 92.4% |
The table shows that the percentage of term matches when training an MT system using glossary materials as a translation memory is much lower than the percentage of matches when connecting the glossary to an AI model. The approach for selecting automated translation customization depending on the language material for training is as follows.
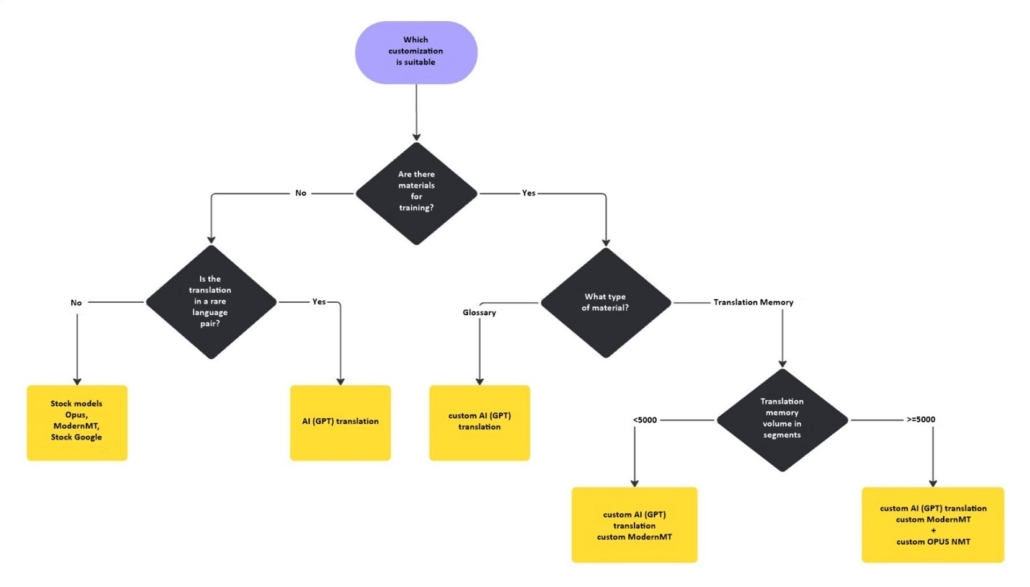
In today’s world of automated translation, there are no universal solutions. The choice between machine translation and AI models often depends on specific tasks, language pairs, and the language data available for customization. Janus successfully combines both approaches, using customization to create highly specialized models for translating texts on specific topics and in particular language pairs.

Machine Translation Specialist
Ksenia Dmitrieva
Ksenia has been with the Research & Development department at Janus since 2024. She graduated with a bachelor’s degree in Translation and Translation Studies from Herzen State Pedagogical University and is currently pursuing a master’s degree in Digital Linguistics. Ksenia specializes in training machine translation (MT) and LLM (AI) systems to improve translation quality and adapt solutions to the needs of specific sectors, as well as in evaluating translation quality using automatic metrics (such as BLEU, TER, and BERTScore).









